444 Alaska Avenue
Suite #BAA205 Torrance, CA 90503 USA
+1 424 999 9627
24/7 Customer Support
sales@markwideresearch.com
Email us at

Market Overview
The Global AI Training Dataset market has experienced remarkable growth in recent years, driven by the increasing demand for high-quality data to train artificial intelligence (AI) models. AI training datasets play a crucial role in enabling accurate and robust AI algorithms, machine learning models, and deep neural networks. In this market overview, we delve into the meaning of AI training datasets, provide key insights into market trends and dynamics, analyze the market drivers, restraints, and opportunities, examine regional variations, discuss the competitive landscape, and present future outlooks for this dynamic industry.
Meaning
AI training datasets refer to collections of data used to train AI models and algorithms. These datasets are carefully curated and labeled to provide accurate and comprehensive information for AI systems. AI training datasets encompass various types of data, including text, images, audio, video, and sensor data. These datasets serve as the foundation for AI model development and enable machines to learn and make predictions based on patterns and examples. High-quality and diverse training datasets are crucial to achieving reliable and effective AI outcomes.
Executive Summary
The Global AI Training Dataset market has witnessed significant growth due to the increasing adoption of AI technologies across industries, rising demand for accurate and diverse training data, and advancements in data collection and labeling techniques. This market presents substantial opportunities for industry participants and stakeholders. However, challenges related to data privacy, data bias, and the availability of large-scale labeled datasets pose as market restraints. The market is dynamic, with various technological advancements and strategic collaborations taking place among key industry players. Regional variations are observed in the adoption and availability of AI training datasets, with North America leading the market followed by Europe and Asia-Pacific.
Important Note: The companies listed in the image above are for reference only. The final study will cover 18–20 key players in this market, and the list can be adjusted based on our client’s requirements.
Key Market Insights
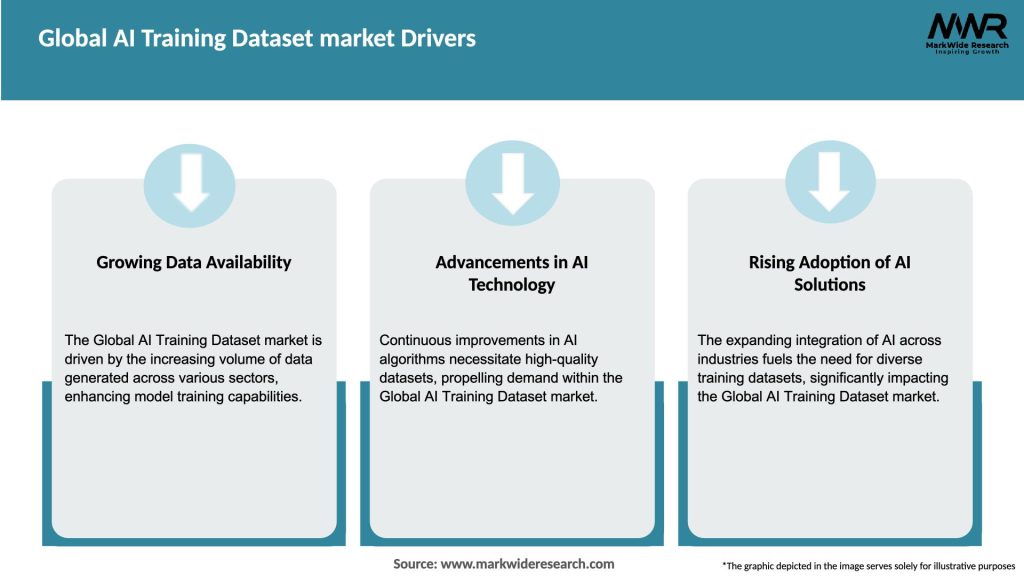
The Global AI Training Dataset market is primarily driven by:
Market Drivers
Market Restraints
Market Opportunities
Market Dynamics
The Global AI Training Dataset market is characterized by intense competition, rapid technological advancements, and evolving industry standards. Key industry players are investing in research and development to enhance data collection and labeling techniques, improve dataset quality, and develop innovative solutions. The market is witnessing collaborations, partnerships, and acquisitions to expand dataset offerings and address data privacy and bias concerns. Increasing awareness among industries about the importance of high-quality training data and the benefits of AI model accuracy is expected to drive market growth.
Regional Analysis
The adoption and availability of AI training datasets vary across different regions:
Competitive Landscape
Leading Companies in the Global AI Training Dataset Market
Please note: This is a preliminary list; the final study will feature 18–20 leading companies in this market. The selection of companies in the final report can be customized based on our client’s specific requirements.
Segmentation
The market for AI training datasets can be segmented based on data type, industry vertical, and application. Data types include text, images, audio, video, and sensor data. Industry verticals consist of healthcare, finance, e-commerce, automotive, and others. Applications range from natural language processing and computer vision to recommendation systems and autonomous systems.
Category-wise Insights
Key Benefits for Industry Participants and Stakeholders
AI training datasets offer numerous benefits for industry participants and stakeholders:
SWOT Analysis
Strengths:
Weaknesses:
Opportunities:
Threats:
Market Key Trends
Covid-19 Impact
The Covid-19 pandemic has highlighted the importance of AI technologies and the need for high-quality training datasets. The pandemic has led to increased demand for AI-powered solutions for healthcare, remote work, and digital services. The availability of diverse and labeled datasets has been crucial for developing accurate AI models for tasks such as diagnostics, drug discovery, and sentiment analysis during the pandemic.
Key Industry Developments
Analyst Suggestions
Future Outlook
The Global AI Training Dataset market is poised for significant growth in the coming years. The increasing adoption of AI technologies across industries, advancements in data collection and labeling techniques, and the growing emphasis on dataset quality and diversity drive market growth. Despite challenges related to data privacy, bias mitigation, and dataset availability, the market offers substantial opportunities for industry participants and stakeholders. Continued investments in research and development, strategic collaborations, and adherence to ethical practices will shape the future of AI training datasets, enabling the development of accurate and reliable AI models across industries.
Conclusion
AI training datasets are the backbone of accurate and reliable AI model development. The Global AI Training Dataset market has witnessed significant growth, fueled by the increasing demand for high-quality and diverse training data. Despite challenges related to data privacy, bias mitigation, and dataset availability, the market offers substantial opportunities for industry participants. Continued investments in research and development, strategic collaborations, and adherence to ethical practices will shape the future of AI training datasets, enabling the development of accurate and robust AI models that drive transformative advancements in various industries.
What is AI Training Dataset?
AI Training Dataset refers to a collection of data used to train artificial intelligence models, enabling them to learn patterns and make predictions. These datasets can include images, text, audio, and other forms of data that are essential for developing machine learning algorithms.
What are the key players in the Global AI Training Dataset market?
Key players in the Global AI Training Dataset market include companies like Google, Microsoft, and Amazon, which provide extensive datasets and tools for AI development. Other notable companies include IBM and OpenAI, among others.
What are the main drivers of growth in the Global AI Training Dataset market?
The growth of the Global AI Training Dataset market is driven by the increasing demand for AI applications across various industries, such as healthcare, finance, and automotive. Additionally, advancements in machine learning technologies and the need for high-quality data to improve AI model accuracy are significant factors.
What challenges does the Global AI Training Dataset market face?
The Global AI Training Dataset market faces challenges such as data privacy concerns, the need for data standardization, and the difficulty in obtaining diverse and representative datasets. These issues can hinder the development and deployment of effective AI models.
What opportunities exist in the Global AI Training Dataset market?
Opportunities in the Global AI Training Dataset market include the potential for creating specialized datasets for niche applications, such as autonomous vehicles and personalized medicine. Additionally, the rise of synthetic data generation presents new avenues for enhancing dataset diversity and quality.
What trends are shaping the Global AI Training Dataset market?
Trends shaping the Global AI Training Dataset market include the increasing use of synthetic data, the integration of ethical considerations in data collection, and the growing emphasis on data quality over quantity. These trends are influencing how datasets are created and utilized in AI development.
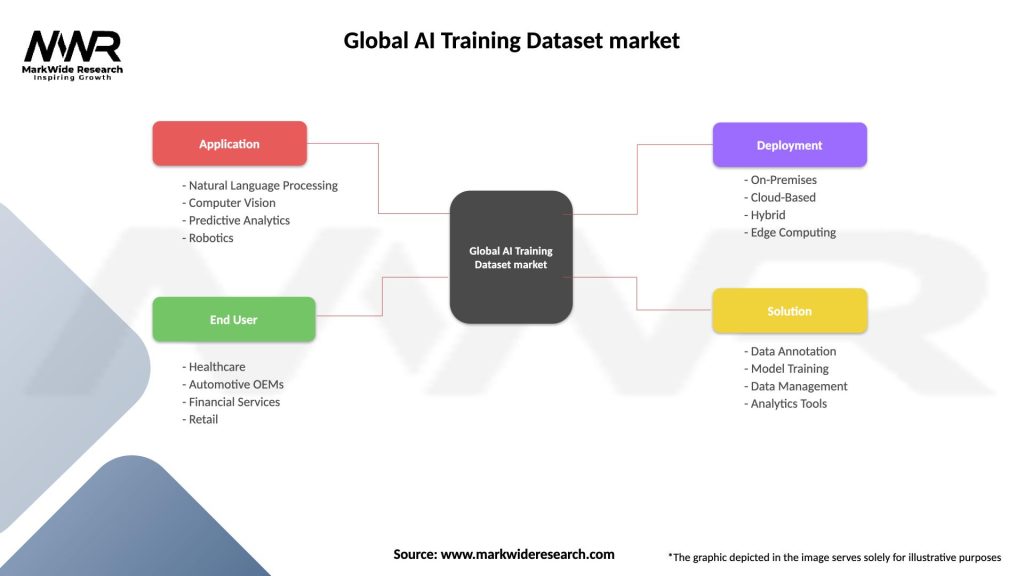
Global AI Training Dataset market
| Segmentation Details | Description |
|---|---|
| Application | Natural Language Processing, Computer Vision, Predictive Analytics, Robotics |
| End User | Healthcare, Automotive OEMs, Financial Services, Retail |
| Deployment | On-Premises, Cloud-Based, Hybrid, Edge Computing |
| Solution | Data Annotation, Model Training, Data Management, Analytics Tools |
Please note: The segmentation can be entirely customized to align with our client’s needs.
Leading Companies in the Global AI Training Dataset Market
Please note: This is a preliminary list; the final study will feature 18–20 leading companies in this market. The selection of companies in the final report can be customized based on our client’s specific requirements.
North America
o US
o Canada
o Mexico
Europe
o Germany
o Italy
o France
o UK
o Spain
o Denmark
o Sweden
o Austria
o Belgium
o Finland
o Turkey
o Poland
o Russia
o Greece
o Switzerland
o Netherlands
o Norway
o Portugal
o Rest of Europe
Asia Pacific
o China
o Japan
o India
o South Korea
o Indonesia
o Malaysia
o Kazakhstan
o Taiwan
o Vietnam
o Thailand
o Philippines
o Singapore
o Australia
o New Zealand
o Rest of Asia Pacific
South America
o Brazil
o Argentina
o Colombia
o Chile
o Peru
o Rest of South America
The Middle East & Africa
o Saudi Arabia
o UAE
o Qatar
o South Africa
o Israel
o Kuwait
o Oman
o North Africa
o West Africa
o Rest of MEA

