444 Alaska Avenue
Suite #BAA205 Torrance, CA 90503 USA
+1 424 999 9627
24/7 Customer Support
sales@markwideresearch.com
Email us at

Market Overview
Apache Spark is a widely adopted open-source distributed computing system that has gained significant traction in the technology market. It provides a powerful and scalable platform for processing large datasets and performing complex analytics tasks. With its ability to handle real-time data processing, machine learning, and graph analytics, Apache Spark has become a cornerstone of big data processing and analytics.
Meaning
Apache Spark is a unified analytics engine designed for big data processing and analytics. It is known for its speed, ease of use, and versatility. Spark offers a high-level programming interface that allows developers to write applications in Java, Scala, Python, and R. It supports a wide range of data processing tasks, including batch processing, interactive queries, streaming, and machine learning.
Executive Summary
The Apache Spark market is experiencing rapid growth due to the increasing demand for big data analytics solutions. Spark’s ability to process large volumes of data in real-time, its scalability, and its support for a variety of programming languages make it a popular choice for organizations across different industries. The market is expected to continue its growth trajectory in the coming years as more businesses realize the value of big data analytics and invest in technologies like Apache Spark.
Important Note: The companies listed in the image above are for reference only. The final study will cover 18–20 key players in this market, and the list can be adjusted based on our client’s requirements.
Key Market Insights
Market Drivers
Market Restraints
Market Opportunities
Market Dynamics
The Apache Spark market is dynamic and influenced by various factors, including technological advancements, changing customer demands, and competitive landscape. Continuous innovation and improvements in Spark’s performance and capabilities, along with the expansion of its ecosystem, contribute to the market’s growth. Additionally, partnerships, collaborations, and strategic acquisitions by key players in the market shape the competitive landscape and influence market dynamics.
Regional Analysis
The Apache Spark market has a global presence, with significant adoption across various regions. North America, with its established technology landscape and the presence of major technology players, holds a significant share in the market. Europe and Asia Pacific are also witnessing substantial growth in the adoption of Apache Spark, driven by the increasing demand for big data analytics solutions and the growth of digital transformation initiatives in these regions.
Competitive Landscape
Leading Companies in the Apache Spark Market:
Please note: This is a preliminary list; the final study will feature 18–20 leading companies in this market. The selection of companies in the final report can be customized based on our client’s specific requirements.

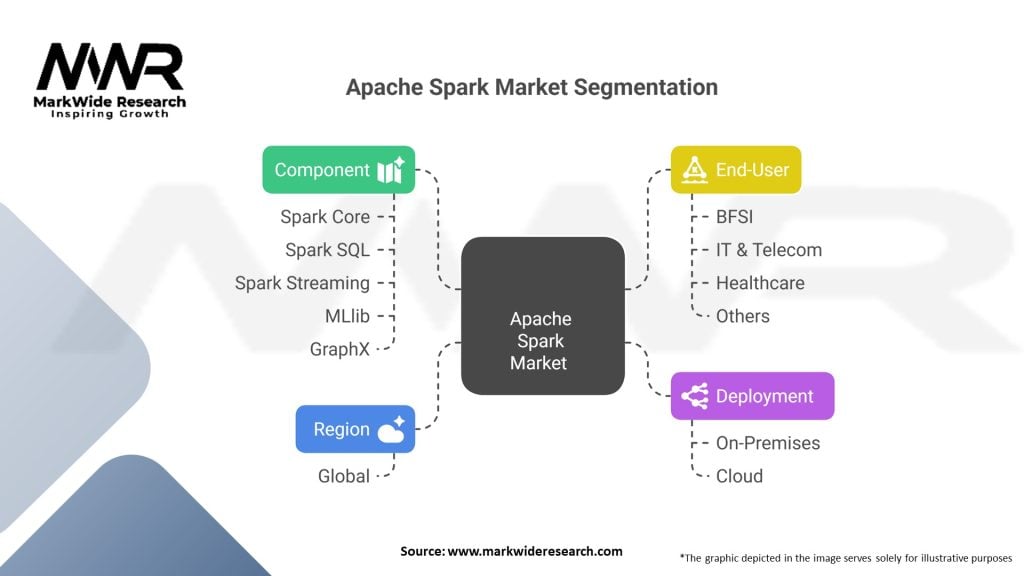
Segmentation
The Apache Spark market can be segmented based on deployment mode, organization size, industry vertical, and geography.
Based on deployment mode:
Based on organization size:
Based on industry vertical:
Category-wise Insights
Key Benefits for Industry Participants and Stakeholders
SWOT Analysis
Market Key Trends
Covid-19 Impact
The Covid-19 pandemic has accelerated the adoption of digital technologies and data-driven decision-making across industries. Apache Spark, with its capabilities for real-time analytics and processing, has played a crucial role in helping organizations analyze and respond to the rapidly changing business landscape during the pandemic. Industries such as healthcare, retail, and logistics have relied on Apache Spark to process and analyze real-time data related to patient care, supply chain disruptions, and customer behavior. The pandemic has underscored the importance of data-driven insights, further fueling the demand for Apache Spark and similar technologies.
Key Industry Developments
Analyst Suggestions
Future Outlook
The future of the Apache Spark market looks promising, with continued growth expected. As the volume and complexity of data continue to increase, organizations will increasingly rely on technologies like Apache Spark to process and analyze their data efficiently. The integration of Spark with emerging technologies, such as edge computing, IoT, and deep learning, will open new opportunities and use cases for Apache Spark. Moreover, advancements in Spark’s capabilities, ecosystem expansions, and ongoing community contributions are likely to further strengthen its position as a leading big data processing and analytics platform.
Conclusion
Apache Spark has emerged as a powerful and versatile analytics engine for big data processing. Its ability to handle large volumes of data, perform real-time analytics, and support multiple programming languages makes it a popular choice among organizations across industries. The market for Apache Spark is driven by the increasing demand for data-driven insights, scalability, and real-time analytics. While challenges such as the shortage of skilled professionals and implementation complexity exist, the market offers significant opportunities in cloud-based deployments and integration with emerging technologies. With continuous advancements and innovations, the future outlook for Apache Spark remains positive, and it is expected to play a crucial role in the evolving landscape of big data analytics.
What is Apache Spark?
Apache Spark is an open-source unified analytics engine designed for large-scale data processing. It provides high-level APIs in Java, Scala, Python, and R, and supports various data processing tasks such as batch processing, stream processing, and machine learning.
What are the key players in the Apache Spark market?
Key players in the Apache Spark market include Databricks, Cloudera, and IBM, which offer various solutions and services built on the Spark framework. These companies focus on enhancing data analytics capabilities and providing cloud-based services, among others.
What are the growth factors driving the Apache Spark market?
The Apache Spark market is driven by the increasing demand for real-time data processing and analytics, the rise of big data technologies, and the growing adoption of cloud computing. Organizations are leveraging Spark for its speed and efficiency in handling large datasets.
What challenges does the Apache Spark market face?
The Apache Spark market faces challenges such as the complexity of integration with existing systems and the need for skilled professionals to manage Spark applications. Additionally, competition from other data processing frameworks can hinder market growth.
What opportunities exist in the Apache Spark market?
Opportunities in the Apache Spark market include the expansion of machine learning applications and the increasing use of Spark in various industries such as finance, healthcare, and retail. The growing trend of data-driven decision-making also presents significant potential for Spark solutions.
What trends are shaping the Apache Spark market?
Trends shaping the Apache Spark market include the integration of artificial intelligence and machine learning capabilities, the rise of serverless computing, and the increasing focus on data governance and security. These trends are influencing how organizations utilize Spark for their data analytics needs.
Apache Spark Market Segmentation:
| Segment | Segmentation Details |
|---|---|
| Component | Spark Core, Spark SQL, Spark Streaming, MLlib, GraphX |
| Deployment | On-Premises, Cloud |
| End-User | BFSI, IT & Telecom, Healthcare, Others |
| Region | Global |
Please note: The segmentation can be entirely customized to align with our client’s needs.
Leading Companies in the Apache Spark Market:
Please note: This is a preliminary list; the final study will feature 18–20 leading companies in this market. The selection of companies in the final report can be customized based on our client’s specific requirements.
North America
o US
o Canada
o Mexico
Europe
o Germany
o Italy
o France
o UK
o Spain
o Denmark
o Sweden
o Austria
o Belgium
o Finland
o Turkey
o Poland
o Russia
o Greece
o Switzerland
o Netherlands
o Norway
o Portugal
o Rest of Europe
Asia Pacific
o China
o Japan
o India
o South Korea
o Indonesia
o Malaysia
o Kazakhstan
o Taiwan
o Vietnam
o Thailand
o Philippines
o Singapore
o Australia
o New Zealand
o Rest of Asia Pacific
South America
o Brazil
o Argentina
o Colombia
o Chile
o Peru
o Rest of South America
The Middle East & Africa
o Saudi Arabia
o UAE
o Qatar
o South Africa
o Israel
o Kuwait
o Oman
o North Africa
o West Africa
o Rest of MEA

